Picture this: You hand the world’s smartest AI assistants a coding challenge using tools they’ve barely seen before, then sit back and watch. That’s exactly what a team of Portuguese researchers did, and the results? Well, they’re both impressive and sobering.
The Million Dollar Question
We’ve all heard the hype about AI revolutionizing programming. ChatGPT writes code! Claude debugs functions! But here’s what nobody was really testing: Can these AI systems handle the messy, real-world challenge of scientific programming with obscure libraries? You know, the kind of stuff actual researchers deal with daily?
This isn’t about writing another weather app or sorting algorithm. This is about whether AI can genuinely accelerate scientific discovery by handling complex experimental code. And friends, the answer is complicated.
Setting Up the Ultimate Test
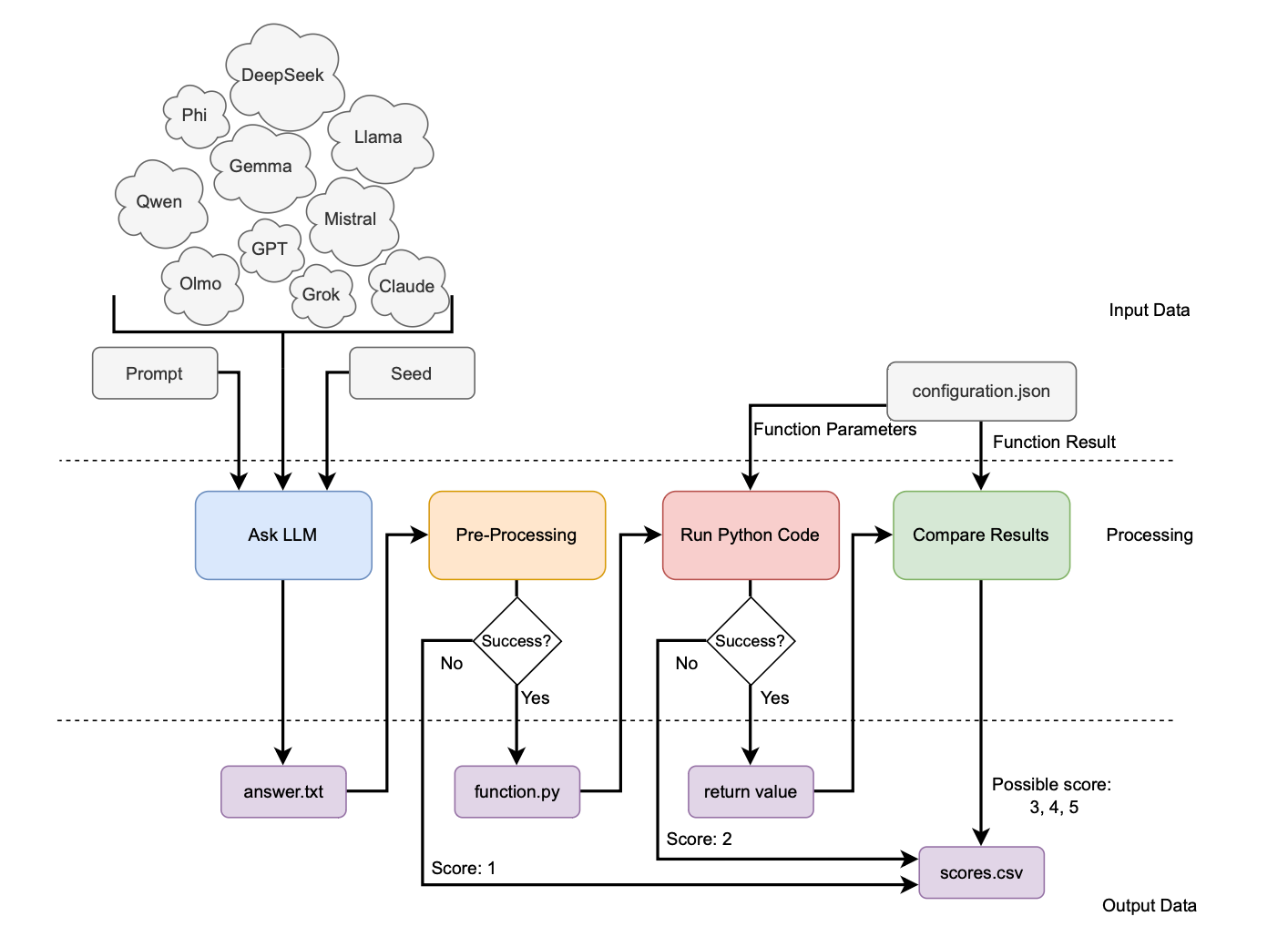
The researchers were clever. Instead of testing these AI models on popular libraries everyone knows (that would be like testing a chef using only salt and pepper), they chose two relatively unknown Python libraries: ParShift for conversation analysis and pyclugen for synthetic data generation.
They gave each AI model detailed instructions, complete with documentation, but zero examples. No hand-holding, no training wheels. Just “here’s what we need, figure it out.” They tested 17 different models, from OpenAI’s GPT-4.1 to Google’s Gemma, Meta’s Llama, and everything in between.
Round One: The Conversation Challenge
The first task seemed deceptively simple. Using ParShift, the AIs needed to analyze conversation files and calculate how often people interrupted each other (technically called “turn usurping”). Think of it as counting how many times someone jumps into a conversation uninvited.
You’d think this would be straightforward, right? Wrong.
Most models crashed and burned. They’d confidently produce code that looked professional and ran without errors but gave completely wrong answers. Others couldn’t even figure out how to access the data properly, throwing error after error like a frustrated programmer at 3 AM.
The kicker? The documentation for ParShift wasn’t crystal clear, and the AIs struggled just like humans would. In fact, this experiment exposed documentation issues so significant that the library authors are now planning major improvements. Sometimes, testing AI is like holding up a mirror to our own unclear instructions.
Round Two: The Data Science Gauntlet
If the first challenge was a pop quiz, the second was a final exam. The AIs had to create synthetic 3D data clusters, apply six different clustering algorithms, evaluate their performance, and return everything in a perfectly formatted table. This is the kind of multi-step scientific workflow that makes graduate students cry.
Here’s where things got interesting. Almost every model made the exact same mistake: they tried to import a function called GaussianMixture from the wrong module. It’s like confidently walking into the wrong classroom because the room number seems logical, even though you’re in the completely wrong building.
Even more fascinating was Phi-4, a smaller model that actually produced beautiful, working code that ran flawlessly. The only problem? It analyzed completely the wrong data, like following a recipe perfectly but using salt instead of sugar. The code was syntactically perfect but semantically wrong, highlighting a fundamental challenge in AI understanding.
The Winner Takes It All
Out of 17 contestants, only GPT-4.1 scored perfectly on both challenges. Every. Single. Time.
Grok 3 came incredibly close, stumbling just once. Mistral Large showed split personality syndrome, acing the harder challenge while struggling with the easier one. But the real story isn’t who won; it’s about what this tells us about AI’s current capabilities.
The smaller, open-source models that many researchers rely on for cost and privacy reasons? They failed spectacularly. Models that performed admirably on simpler coding tasks in previous studies couldn’t handle these real-world scientific challenges. It’s a reality check for anyone thinking they can swap out expensive AI models for cheaper alternatives in scientific work.
Why This Matters More Than You Think
This isn’t just another “AI benchmark” study that tech companies will argue about on Twitter. This research reveals something profound about where we are in the AI revolution.
First, it shows that AI can genuinely handle complex scientific programming, but only the most advanced models can do it reliably. If you’re a researcher hoping to use AI to accelerate your work, you’d better have access to top-tier models and double-check everything they produce.
Second, and perhaps more surprisingly, it demonstrates that AI can be an incredible tool for improving software quality. The experiment uncovered bugs and documentation issues that traditional testing missed. One library had a type-checking bug that slipped through despite 100% test coverage, only revealed when AI tried to use it in unexpected ways.
The Road Ahead
So where does this leave us? We’re in a fascinating transition period. AI isn’t ready to replace scientific programmers, but it’s becoming an invaluable assistant for those who can afford the best models and know how to verify the results.
Think of current AI as that brilliant intern who sometimes has amazing insights but occasionally misunderstands fundamental concepts. You wouldn’t let them run your lab unsupervised, but you’d definitely want them on your team.
The path forward is clear: we need better documentation for scientific libraries, more sophisticated AI training on specialized tools, and honest conversations about what AI can and cannot do in scientific research. The hype cycle suggests AI will revolutionize everything tomorrow. This study suggests it’ll happen, but more gradually and carefully than Silicon Valley might have you believe.
The Bottom Line
This research is a perfect snapshot of AI in 2025: remarkably capable yet surprisingly fragile, brilliant in some ways and baffling in others. Only one AI model could consistently write working scientific code for unfamiliar libraries, and that tells us we’re still in the early chapters of the AI-assisted science story.
But here’s the optimistic take: if we’ve come this far this fast, imagine where we’ll be in another few years. The future of scientific computing isn’t about AI replacing humans; it’s about the incredible science we’ll do together.
Just maybe keep a human in the loop for now. You know, to make sure your AI isn’t trying to import GaussianMixture from the wrong place.
Source: https://arxiv.org/abs/2508.00033